Experiments
DF-ExpEnse is a general exploration technique, and can be seamlessly integrated with existing strategies that finetune pretrained diffusion policies via reinforcement learning to provide sample-efficiency benefits. We integrate DF-ExpEnse with input noise and residual finetuning, and evaluate on a variety of manipulation and locomotion tasks across Robomimic, Gym, and DexMimicGen.
Robomimic Tasks
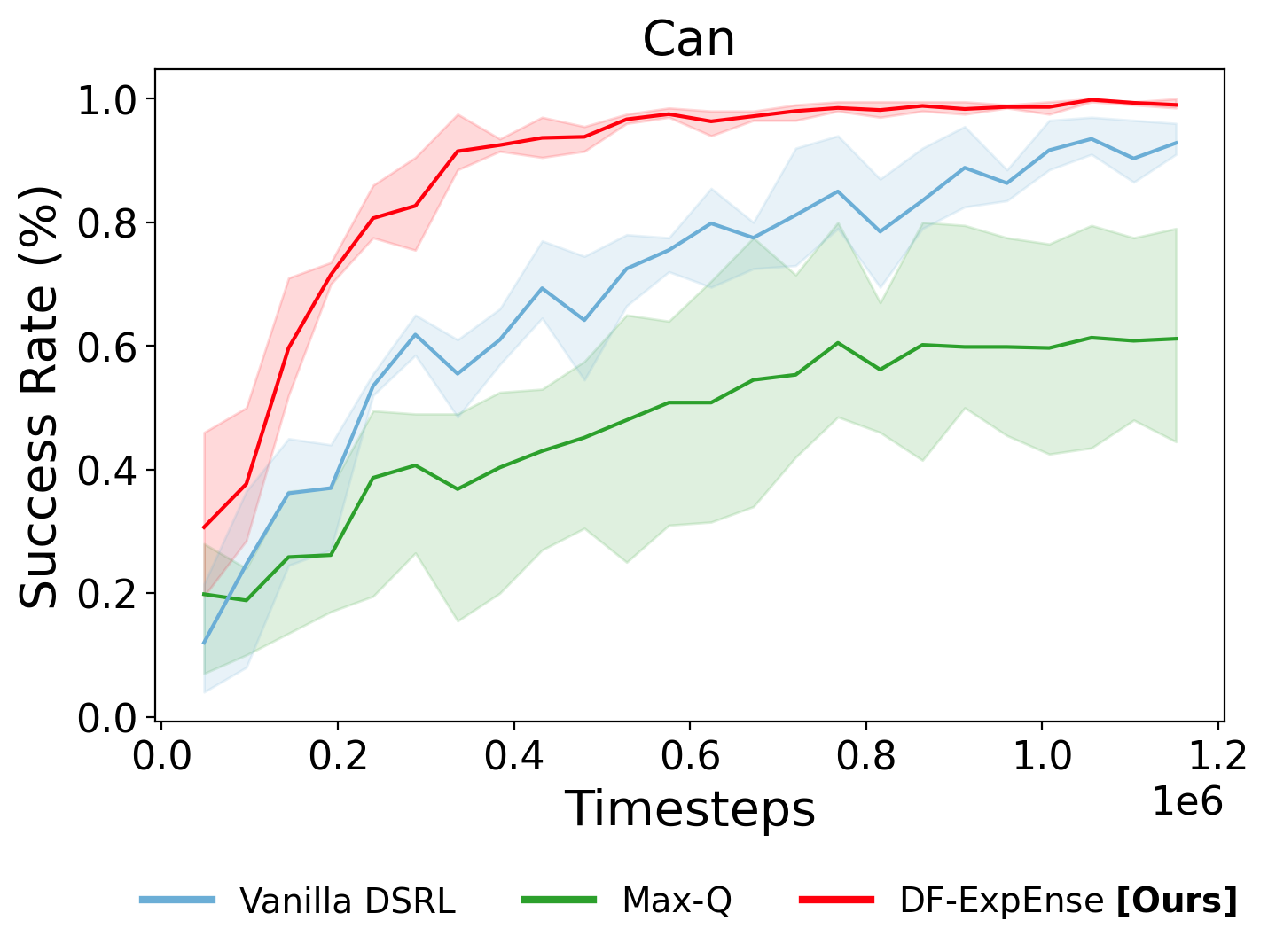
Vanilla DSRL
Timestep: 512,000
Success Rate: ~70%
Max-Q
Timestep: 512,000
Success Rate: ~50%
DF-ExpEnse
Timestep: 512,000
Success Rate: ~90%
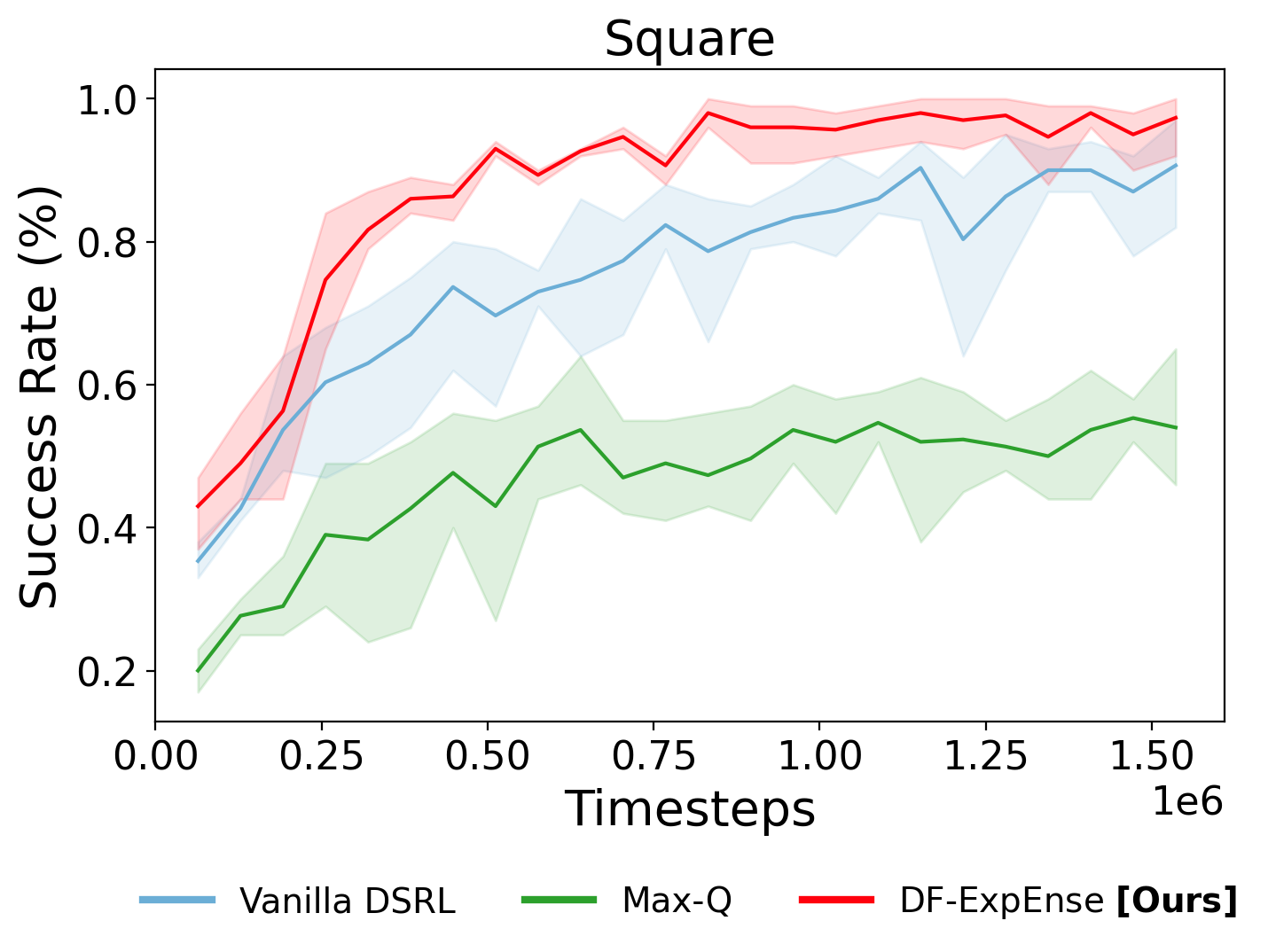
Vanilla DSRL
Timestep: 480,000
Success Rate: ~60%
Max-Q
Timestep: 480,000
Success Rate: ~40%
DF-ExpEnse
Timestep: 480,000
Success Rate: ~90%
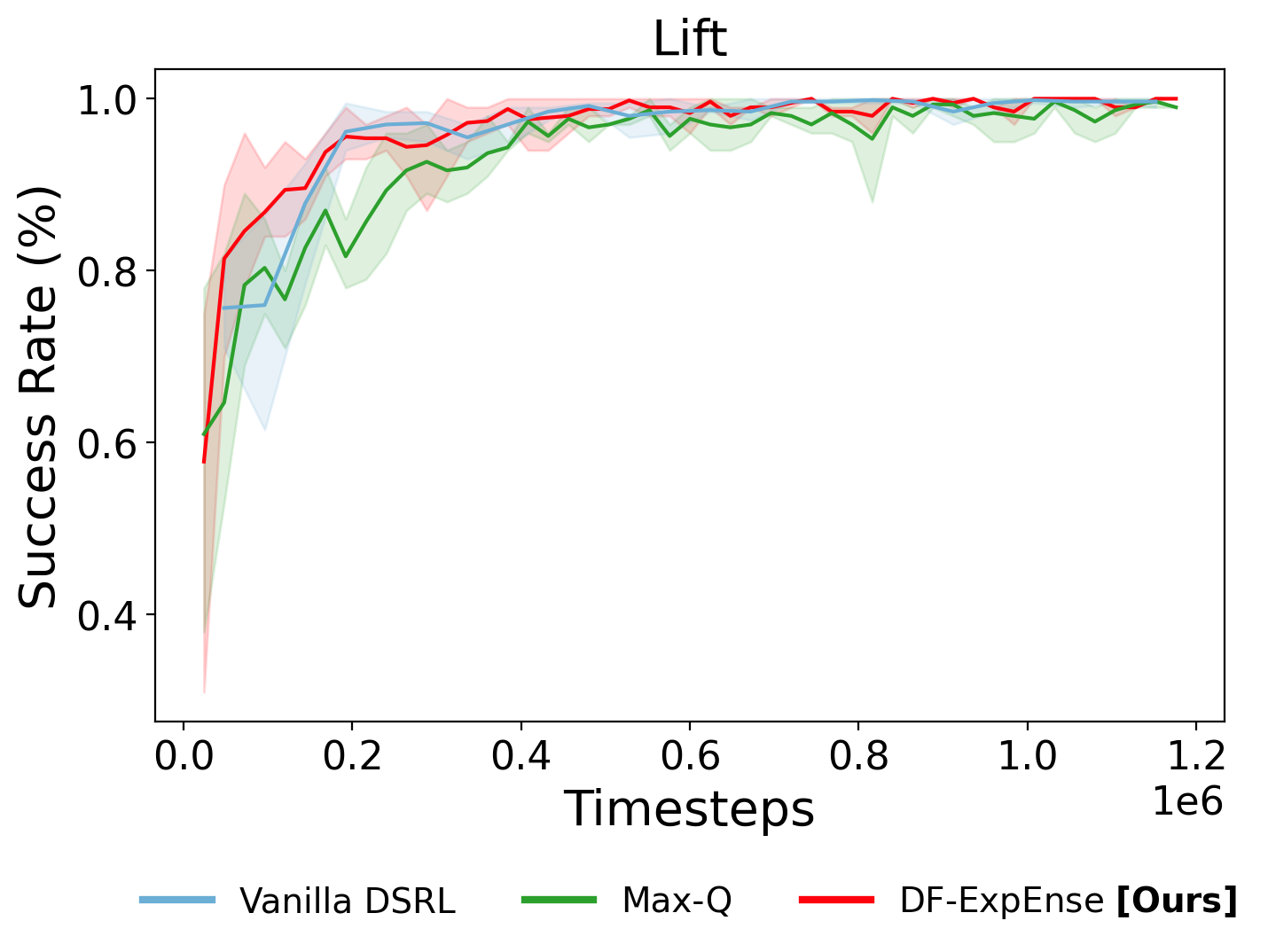
Vanilla DSRL
Timestep: 480,000
Success Rate: ~100%
Max-Q
Timestep: 480,000
Success Rate: ~100%
DF-ExpEnse
Timestep: 480,000
Success Rate: ~100%
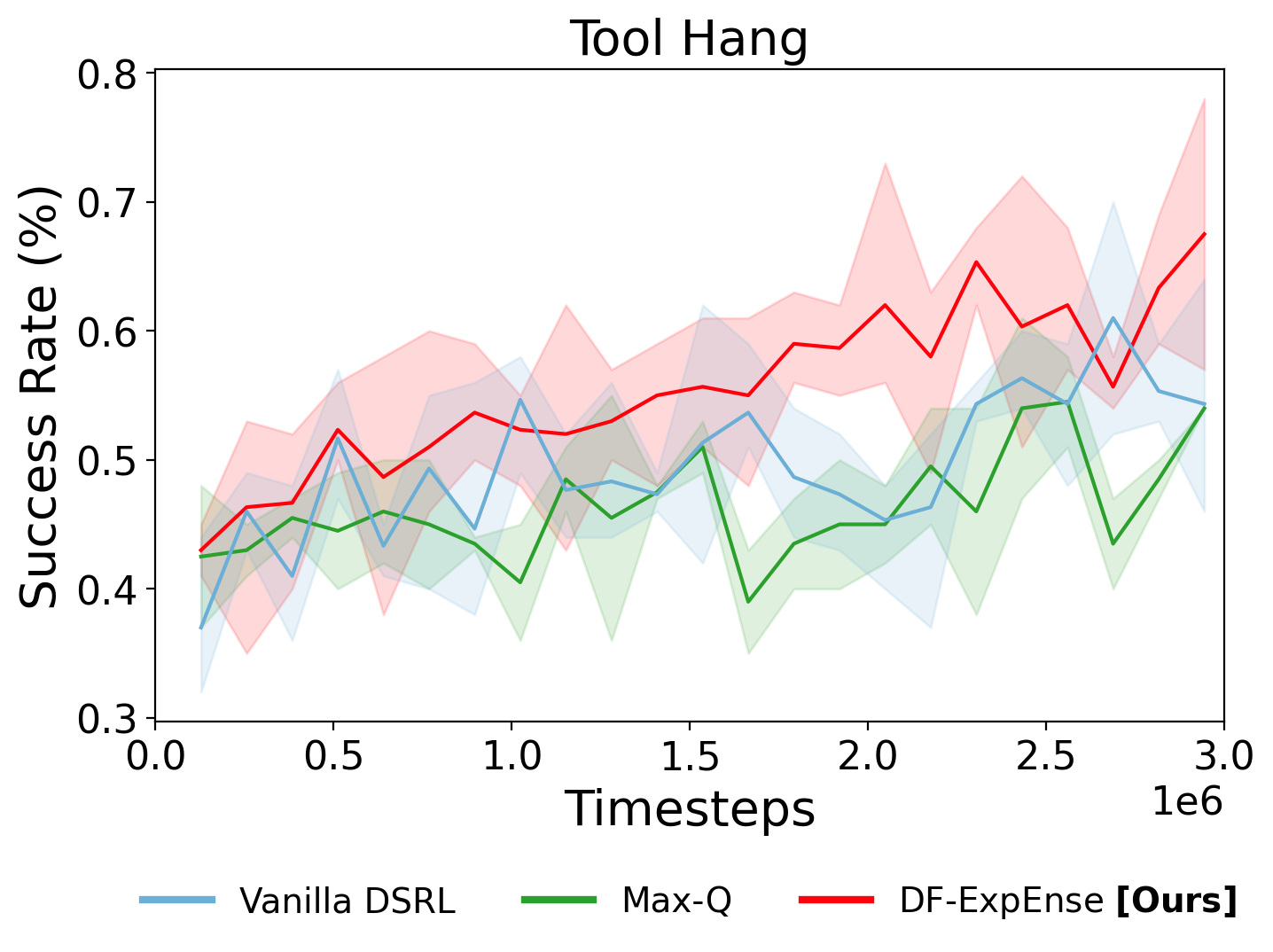
Vanilla DSRL
Timestep: 2,048,000
Success Rate: ~45%
Max-Q
Timestep: 2,048,000
Success Rate: ~45%
DF-ExpEnse
Timestep: 2,048,000
Success Rate: ~60%
DexMimicGen Tasks
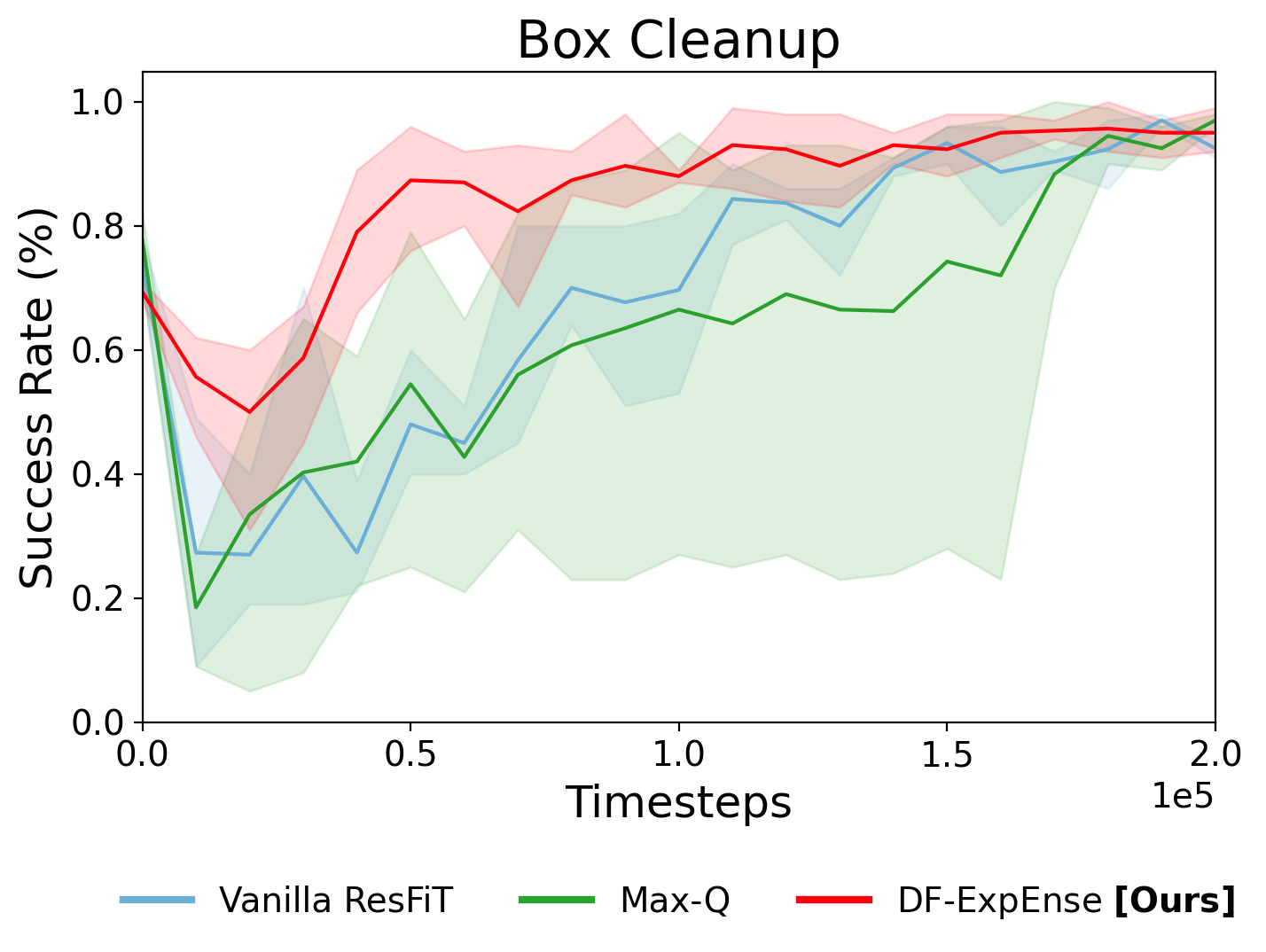
Vanilla ResFiT
Timestep: 50,000
Success Rate: ~40%
Max-Q
Timestep: 50,000
Success Rate: ~50%
DF-ExpEnse
Timestep: 50,000
Success Rate: ~80%
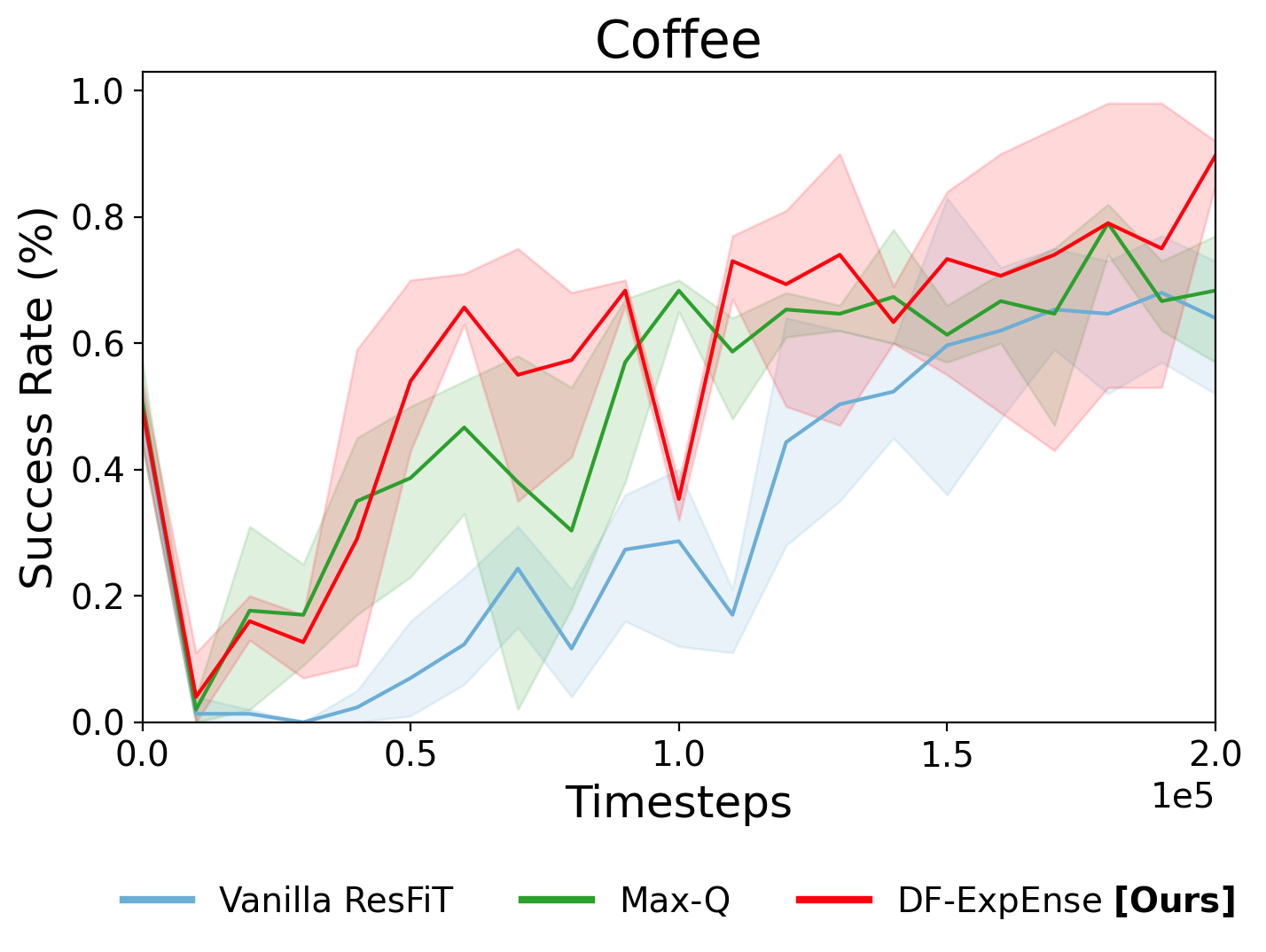
Vanilla ResFiT
Timestep: 50,000
Success Rate: ~10%
Max-Q
Timestep: 50,000
Success Rate: ~40%
DF-ExpEnse
Timestep: 50,000
Success Rate: ~60%
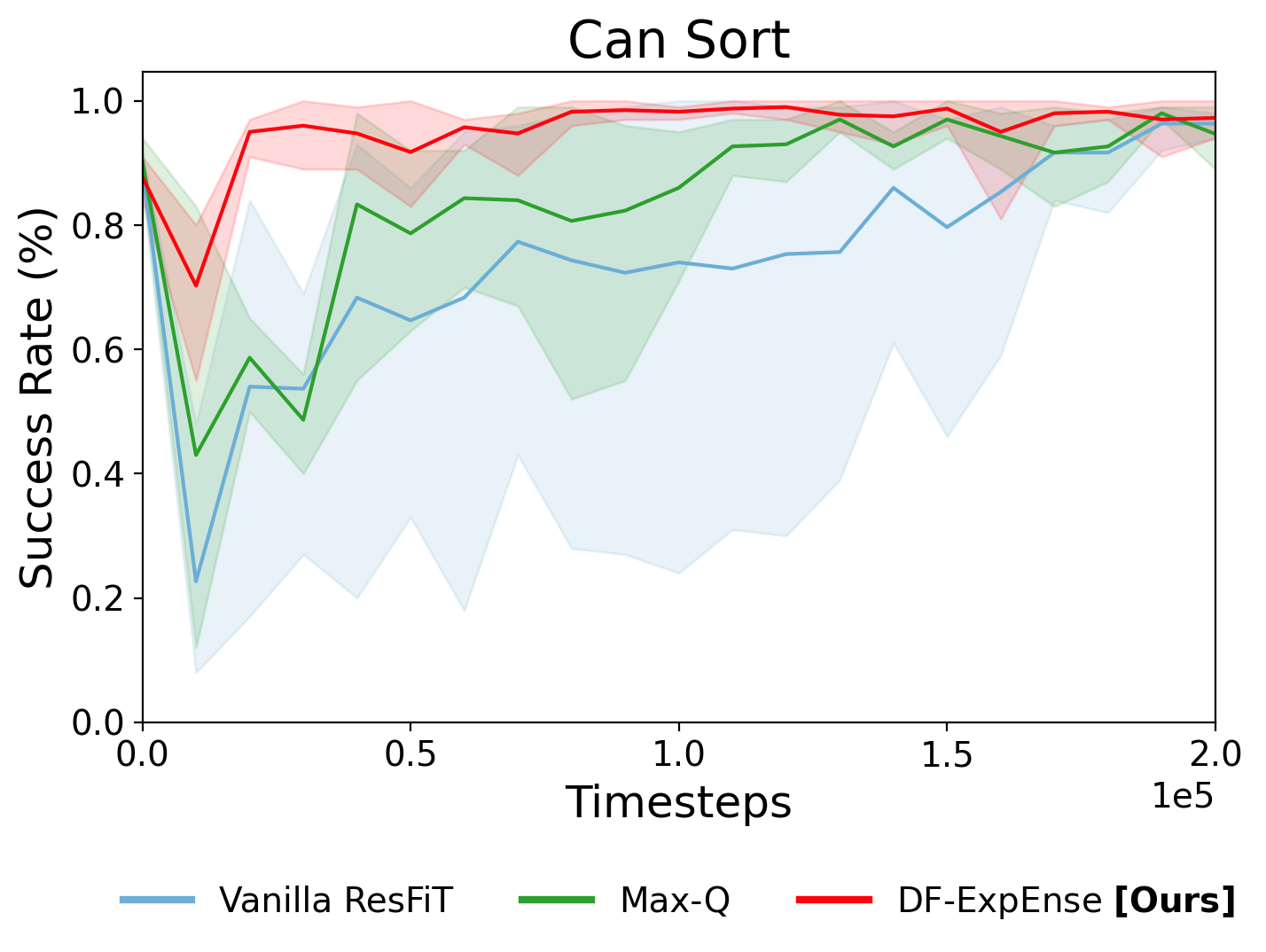
Vanilla ResFiT
Timestep: 50,000
Success Rate: ~60%
Max-Q
Timestep: 50,000
Success Rate: ~80%
DF-ExpEnse
Timestep: 50,000
Success Rate: ~90%
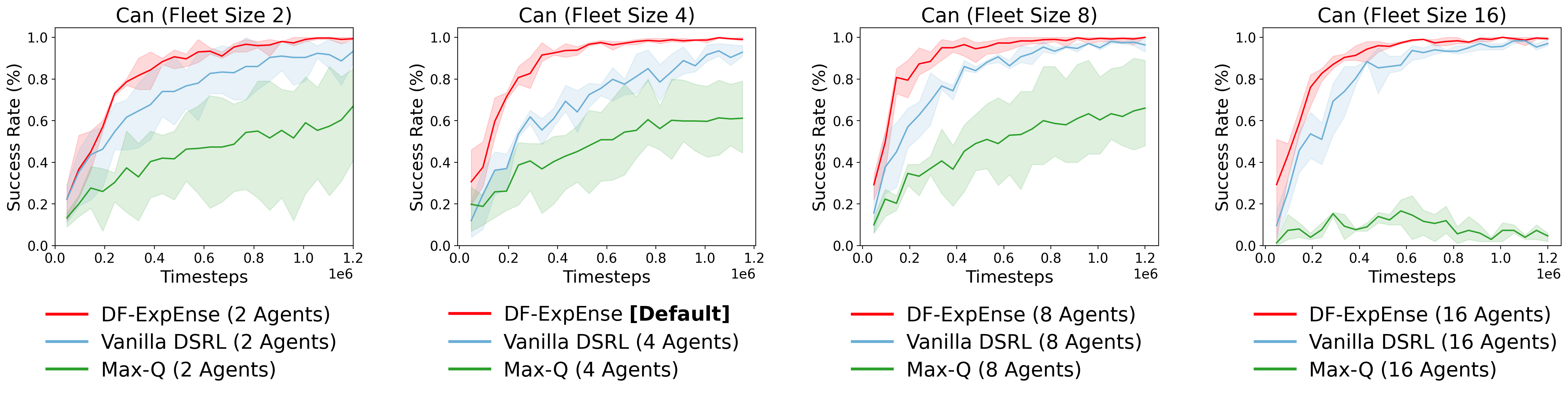
Fleet Size Ablations
Intuitively, larger fleets may provide greater amounts of normalization and collaboration possibilities. We find that performance does decrease below a fleet size of 4, verifying that DF-ExpEnse can leverage larger fleet sizes to help improve sample efficiency. Nevertheless, DF-ExpEnse still reliably outperforms vanilla DSRL and Max-Q across all fleet sizes, large and small.
These findings further reinforce DF-ExpEnse as a robust method that can be integrated with standard reinforcement learning finetuning techniques to provide consistent sample efficiency benefits across a variety of available resource settings.